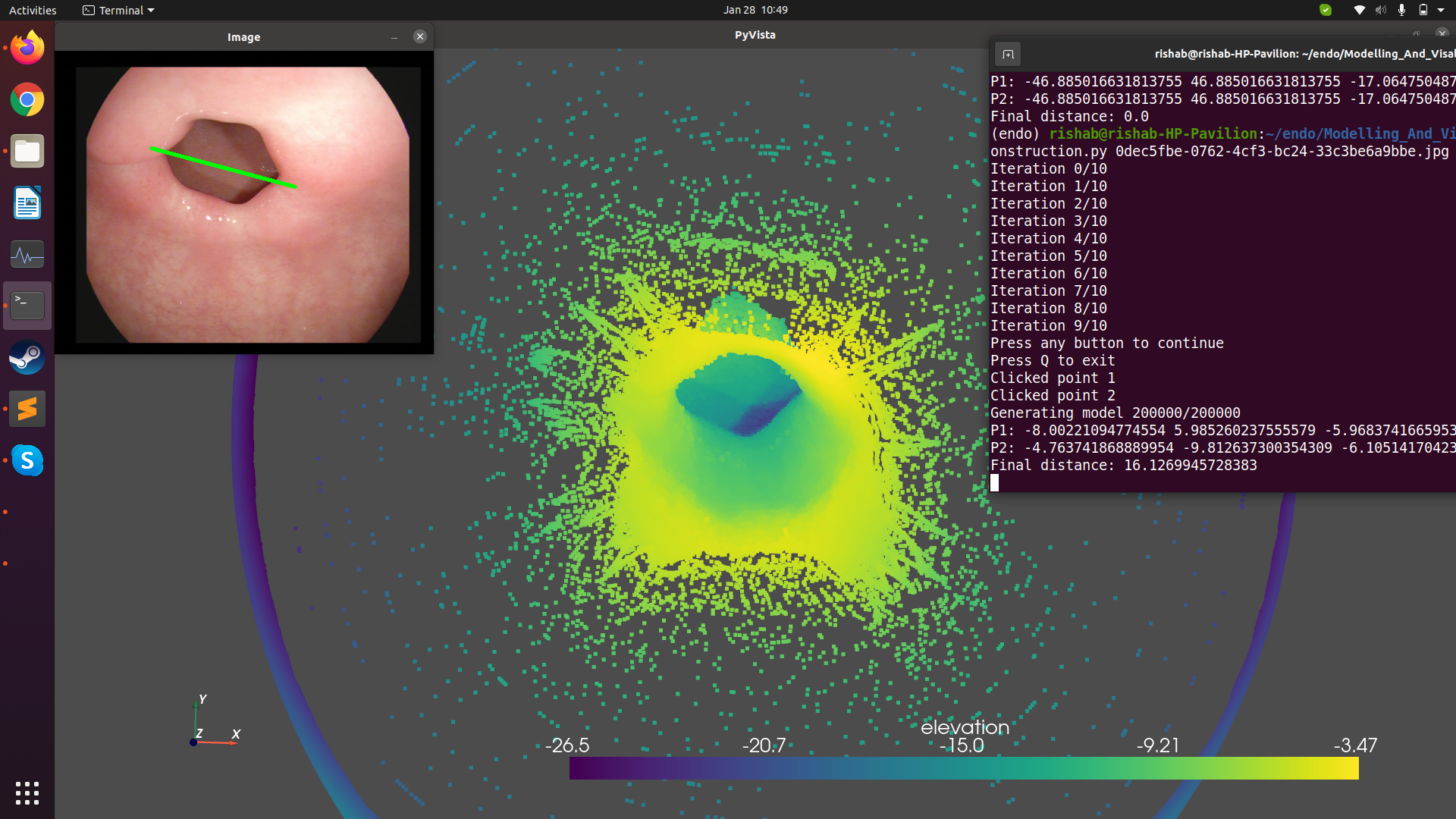
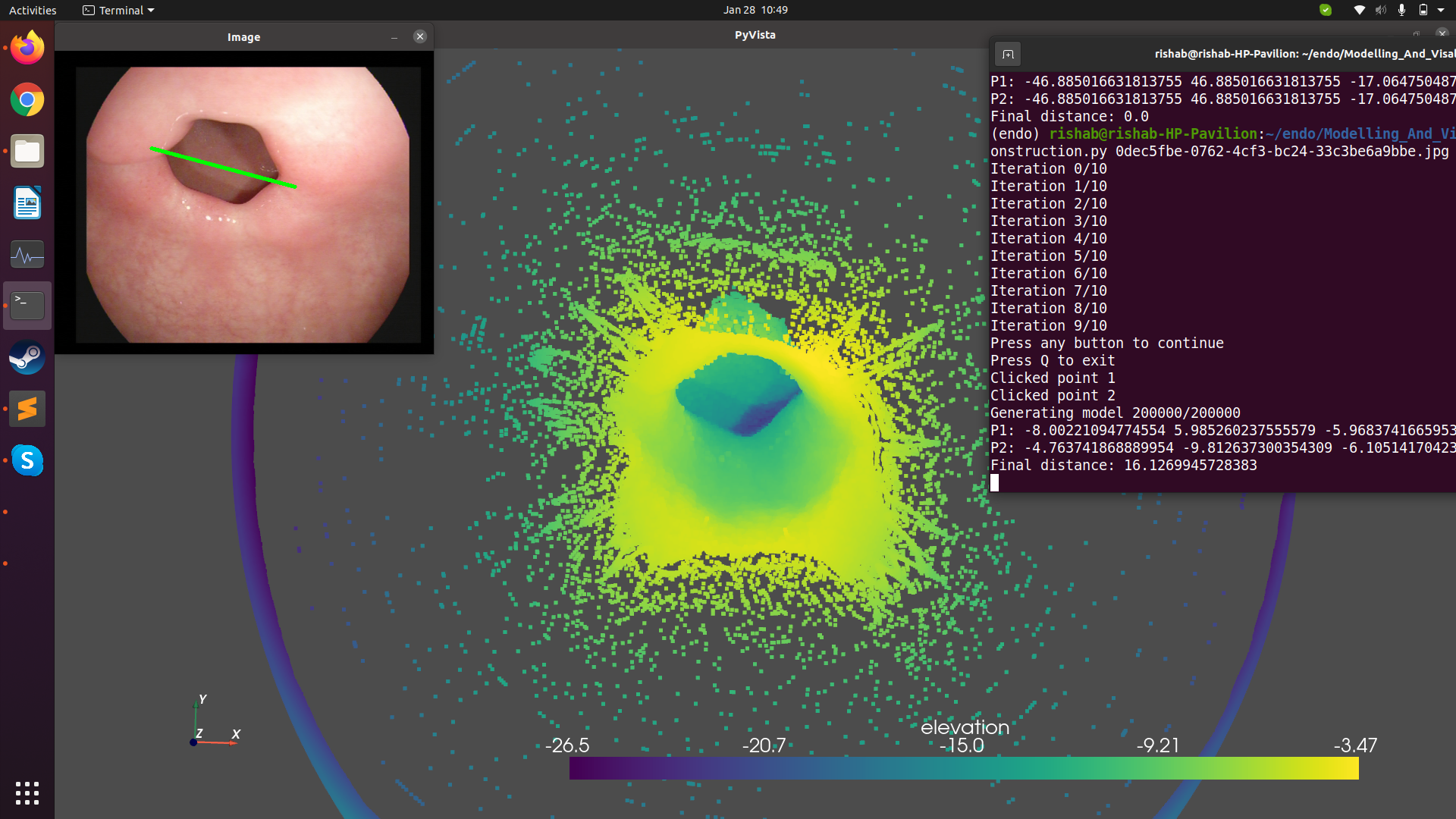
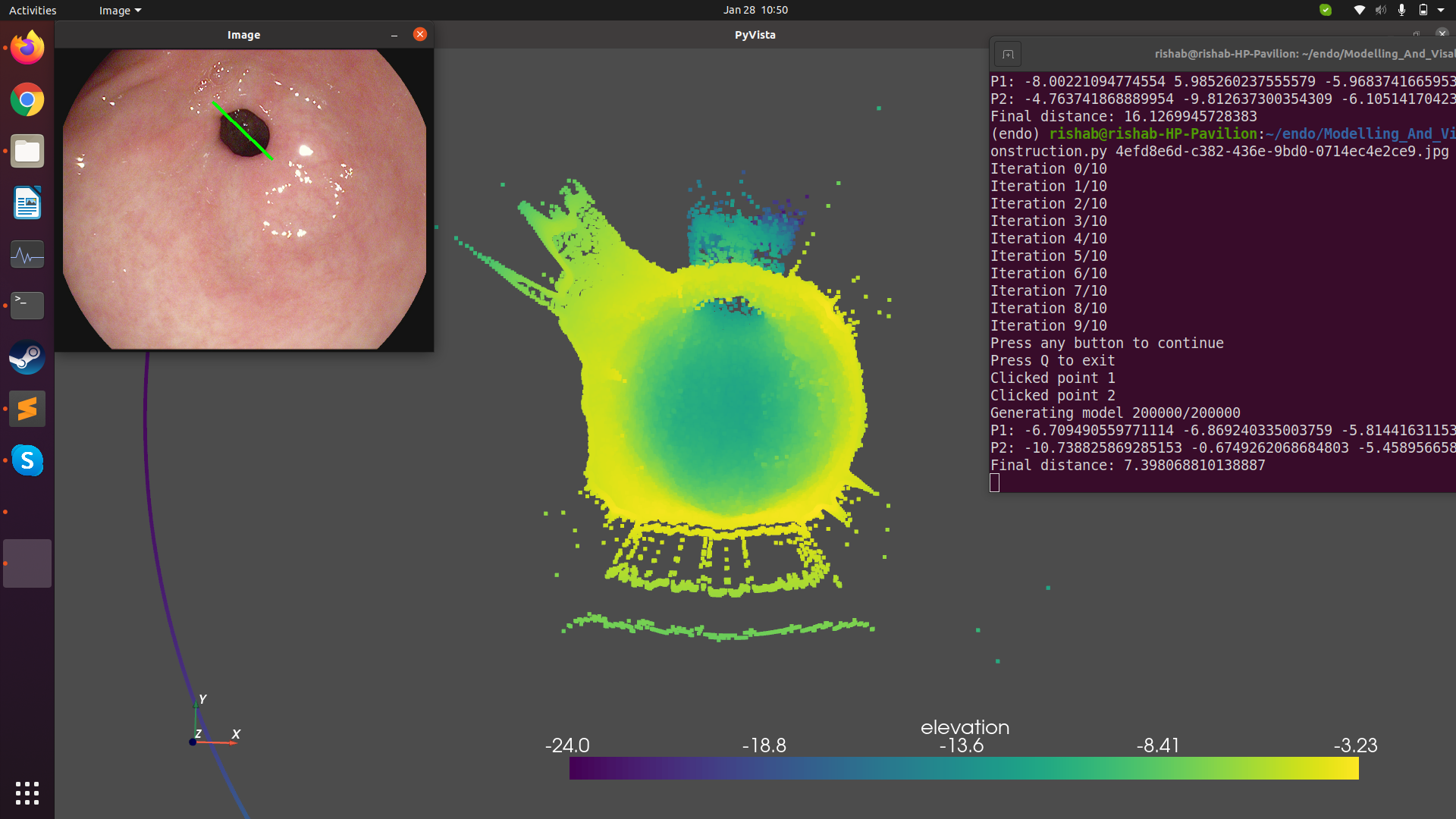

3D reconstruction from RGB endoscopic images
It is difficult for docters and experts to accurately estimate the size of lesions by looking at the incoming endoscopic video feed alone. In this work, we aimed to develop a framework to generate 3D models of the human anatomy using given RGB frames, and congregate the image pixels to create 3D point clouds to help experts make measurements. For this, we used the Shape-from Shading method developed by Vogel-Breuss-Weickwert, solving the resulting PDE. This is under the assumption that the input images are Lambertian, and to ensure this, we make use of inpainting algorithms to remove specularities. We also use an unsupervised training method for estimating depth from consecutive images.